简介语法分析开源神经网络SyntaxNet
SyntaxNet在github文档开源部分介绍了两个模型:词性标注和语法依存分析,论文中还有句子压缩部分内容。[github地址],[相关文档], [对应论文 ]。
对应论文一作为andor,针对三个任务,渐进式介绍了词性标注(part-of-speech),依存分析,句子压缩三个部分工作。依存分析使用了词性标注的输出作为输入特征,而句子压缩则用了前两个任务的结果作为输入特征。 接下来顺序介绍下三个工作:
Part-of-Speech Tagging
训练方式:
从左到右训练,给定一个词,抽取该词和窗口内的特征作为网络的输入,输出为词性标签,无全局解码部分。
实验中特征比较简单,没有用复杂的人工特征设计,特征设计为当前词的$ \pm 3$ 个token窗口的词,类别,字符级别n-gram(up to length3),前4个token的预测tag。得到所有特征拼接起来作为网络的输入。输出为当前位置各个标签的归一化概率。
网络结构如下,参考[7, cheng, 2014]: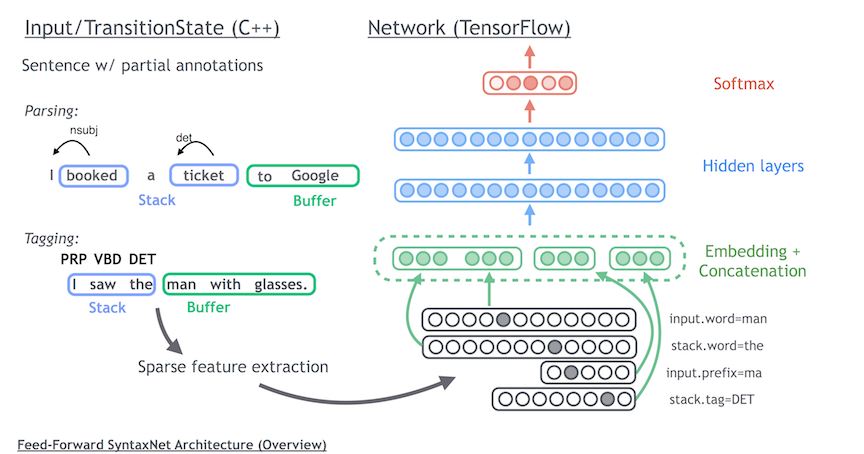
Parsey McParseface[1, Daniel Andor, 2016]在postag上的表现: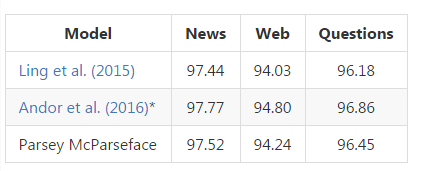
Dependency Parsing: Transition-Based Parsing
简单介绍依存分析任务,词之间的依存关系如下图: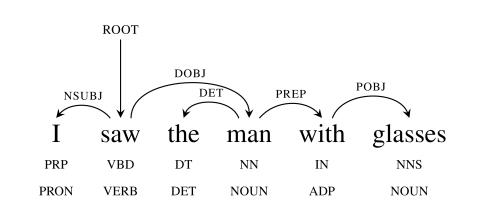
知道词之间的依存关系有助于我们回答问题,例如:
“I saw the man with glasses”,得到如下依存结构后,可以比较容易回答”whom did I see?, who saw the man with glasses?”这类问题。
模型采用arc-standard transition system方式,通过学习一系列操作得到句子的语法树。定义两个结构stack和buffer,有如下三个操作。
- SHIFT: 将单词放入stack中。比从buffer中取出一个词,放入stack
- LEFT_ARC: 从stack中取出头两个词.将第二个词的依存关系指向前一个,箭头向左
- RIGHT_ARC: 从stack中取出头两个词,也是将第二个词指向后一个词,但箭头向右
此为上述三个操作的动图,想了解依存分析更多知识,可以参看论文[2, Nivre 2007] :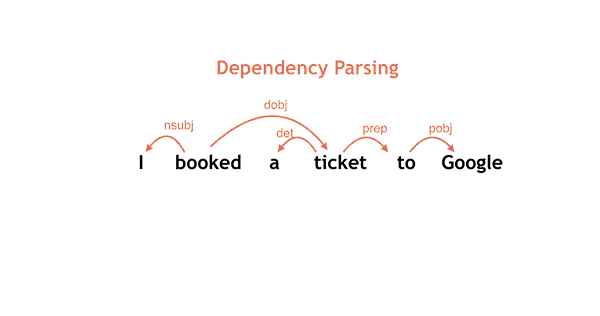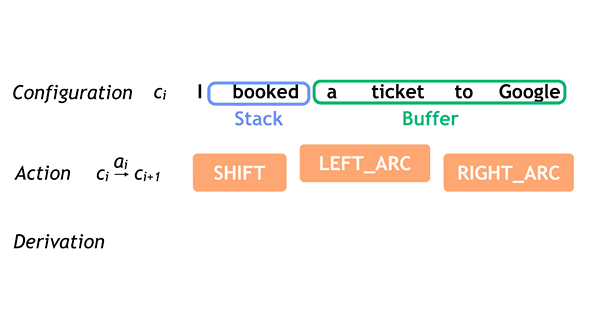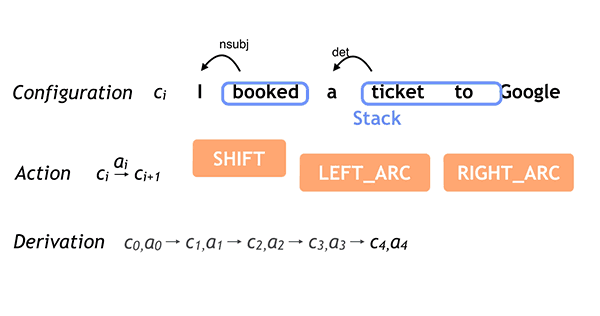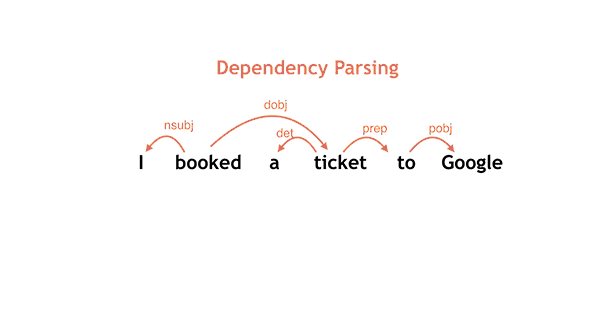
实验中使用的语料与POS任务一样,特征为窗口内的词,POS,附近词的依存关系(预测得到的k-best结果)
训好的模型Parsey McParseface,报告性能如下: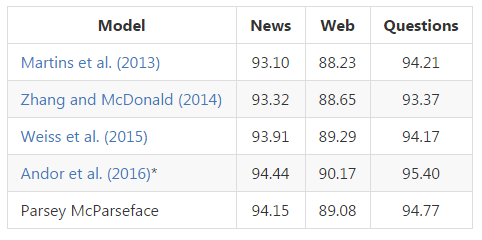
网络结构和前述POS略有区别,在softmax层上增加了CRF层,训练模型分两步:
- local: 使用局部的数据窗口对模型进行pre-train,训练集训顶层为softmax的nn网络,目标函数为局部归一化损失函数,此处得到局部模型。这里和前面训练POStag模型很像,也有用到POStag模型的输出结果。
- global: 保留除了顶层softmax层外其他层的参数,用全局目标函数进行二次训练,得到全局模型。在训练过程中有个细节,如果在某个位置的人工标注tag落在beam(beam search的约束[3, Bottou, 1997])外,则换用另一个包含目标标签的目标函数进行梯度计算。
具体全局模型和局部模型的细节,参见[1, Daniel Andor, 2016],这种训练方式和网络结构更早在[8, Weiss, 2015]中可以看到。文中对于二者性能差异进行了理论论证。训练中采用上述结合的方式,能加快模型的收敛。
注:第一小节介绍POS时,论文POS实验结果最好结果为global Normalization,开源的McParseface文档里对POS任务采用的是local Normalization,这里需要做区分,之前和波大神聊的时候自己没看清。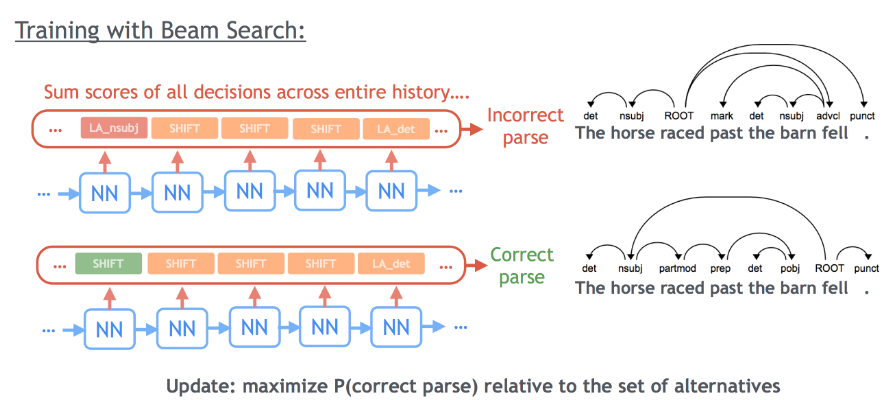
Sentence Compression
句子压缩希望在不发生转义前提下,对句子的非主干部分进行删减。
基线为三层LSTM叠加模型[4, Filippova, 2015],网络结构如下图。decode阶段有部分细节不同:先逆序输入句子中每一个词,再正序输入句子中每一个词开始打分。用到的特征为:当前词的词向量(256维)[5, Mikolov, 2013],前词的label(3维: 1/0/EOF)。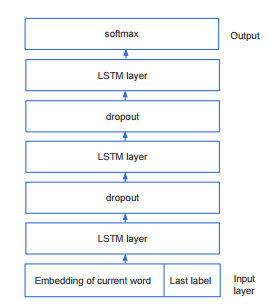
基线单层LSTM结构,输入数据以回文方式进行,应该有Bi-directional LSTM结构上类似的效果。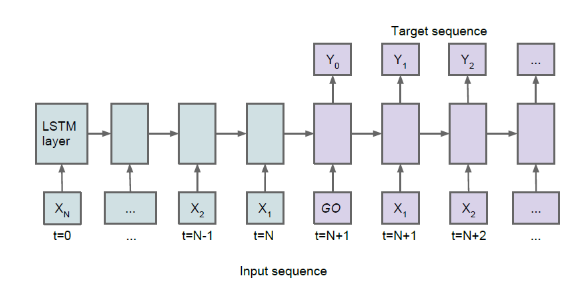
NN的训练往往需要大量的语料才能保证收敛,基线的作者[6, Filippova, 2013]提出了一种启发式构造语料的方法。新闻的标题是高浓缩的句子,从新闻的标题和正文中的句子里,抽取出标题对应的原句,组成压缩句对(原句=>标题)。本文实验中作者抽取了2.3M压缩句对,2M作为训练集,130K作为开发集,160K作为测试集。
实验中句子压缩任务的模型结构和前述任务一致,隐层为400个节点(代码中设定为200*200)。
特征设置:窗口内词的特征,POS,依存关系,前词的预测结果。实验结果如下图: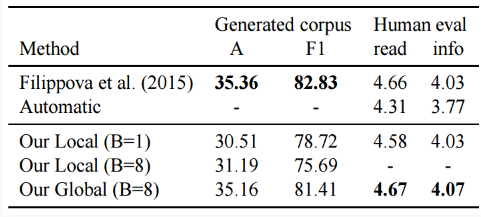
注:andor的论文pos和语法依存效果不错,句子压缩这部分工作则未能胜过Filippova,如果需要调研建议采用Filippova论文里的方法,andor报告里速度100倍于Filippova,应该是没考虑了POS和依存分析两个前置任务的耗时,工程实现上速度可能未必有优势。
[1] Andor D, Alberti C, Weiss D, et al. Globally Normalized Transition-Based Neural Networks[J]. 2016.
[2] Nivre2006] Joakim Nivre. 2006. Inductive Dependency Parsing. Springer-Verlag New York, Inc.
[3] L´eon Bottou, Yann Le Cun, and Yoshua Bengio. 1997. Global training of document processing systems using graph transformer networks. In Proceedings of Computer Vision and Pattern Recognition (CVPR), pages 489–493.
[4]Filippova K, Alfonseca E, Colmenares C A, et al. Sentence Compression by Deletion with LSTMs[C] Conference on Empirical Methods in Natural Language Processing. 2015.
[5] Mikolov, T., I. Sutskever, K. Chen, G. S. Corrado & J. Dean (2013). Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems, pp. 3111–3119.
[6] Filippova K, Altun Y. Overcoming the lack of parallel data in sentence compression[C] 2013.
[7] Chen D, Manning C. A Fast and Accurate Dependency Parser using Neural Networks[C]// Conference on Empirical Methods in Natural Language Processing. 2014.
[8] Weiss D, Alberti C, Collins M, et al. Structured Training for Neural Network Transition-Based Parsing[J]. Computer Science, 2015.
Author: shawnxiao@baidu